
This chapter is mainly about data collection based on the Python language, and this function can be learned as a separate course, because this is a very important course, generally used in big data processing and artificial intelligence, the application provides a large amount of data.
# 网络爬虫
# 导入模块
import urllib.request as req
# 爬取该地址的网页源码
res=req.urlopen(r”https://www.baidu.com”)
# 从爬取的内容中读取信息
html=res.read()
# 读取的信息是字节,需要通过编码格式的转换,才能获得和网页上审查元素的源代码一致
html=html.decode(“UTF-8”)
print(html)
Output:

12.1 Learning of the urllib module
The urllib module is a module that Python provides to us to operate the Internet. Next, we can simply operate, crawling the source code of a web page, which is actually the operation of reviewing elements. Urllib is divided into four parts: 1.request 2.error 3.parse 4.robotparser
Request is the most important and complex of urllibs.
# 网络爬虫 hmi module lcm
# 导入模块
import urllib.request as req
# 爬取该地址的网页源码
res=req.urlopen(r”https://www.baidu.com”)
# 从爬取的内容中读取信息
html=res.read()
# 读取的信息是字节,需要通过编码格式的转换,才能获得和网页上审查元素的源代码一致
html=html.decode(“UTF-8”)
print(html)
12.2 Practice
12.2.1 Crawling Images
Here we come to visit Baidu Pictures, and its website effect is as shown in the picture:
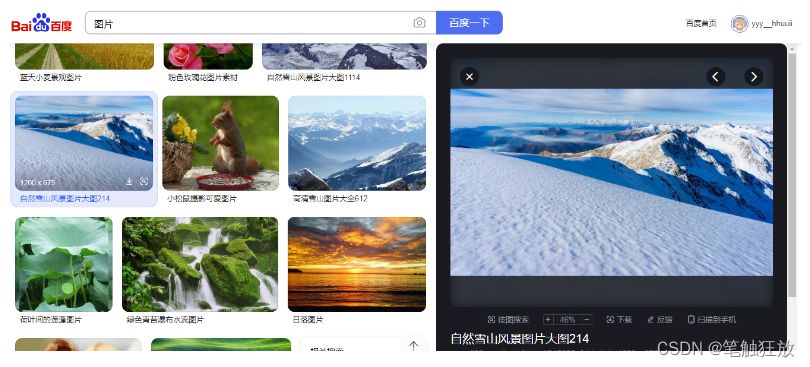
Then we generally want a certain picture, we need to move the mouse to the picture and click the right button, and then save the picture as… Under the specified disk path to our computer. Let’s take a look at how python crawls through code to get the images you want. Let’s first look at the access address corresponding to this picture, right-click to copy the image access address, paste it on the address to access it, whether it can be accessed normally
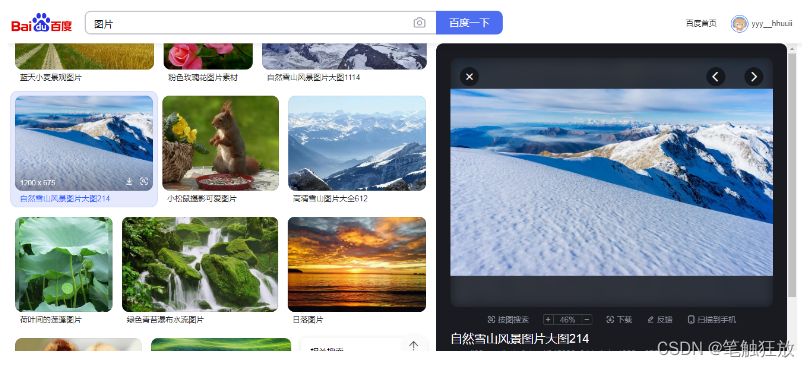
That is, through the access of the address, you can view a certain picture, then we will crawl this picture through the Python crawler.
# 导入模块
import urllib.request as req
#指定猫的访问地址
res=req.urlopen(“https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.jj20.com%2Fup%2Fallimg%2F1113%2F052420110515%2F200524110515-2-1200.jpg&refer=http%3A%2F%2Fimg.jj20.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1662537204&t=69f97612ad5cfcc28f60537007447873”)
# 将猫图片读取,字节保存
cat_img=res.read()
# 指定一个本地路径,用于存储图片,并允许写入字节
f=open(“cat_200_287.jpg”,”wb”)
#将图片存储
f.write(cat_img)
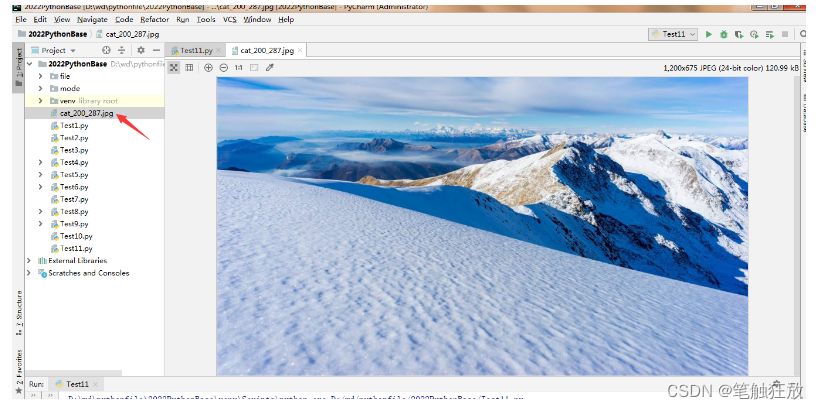
After the execution is complete, you can find that the picture has been crawled under the project path.

12.2.2 Online Text Translation
Open a browser to access Youdao Translation’s website online translation._Youdao
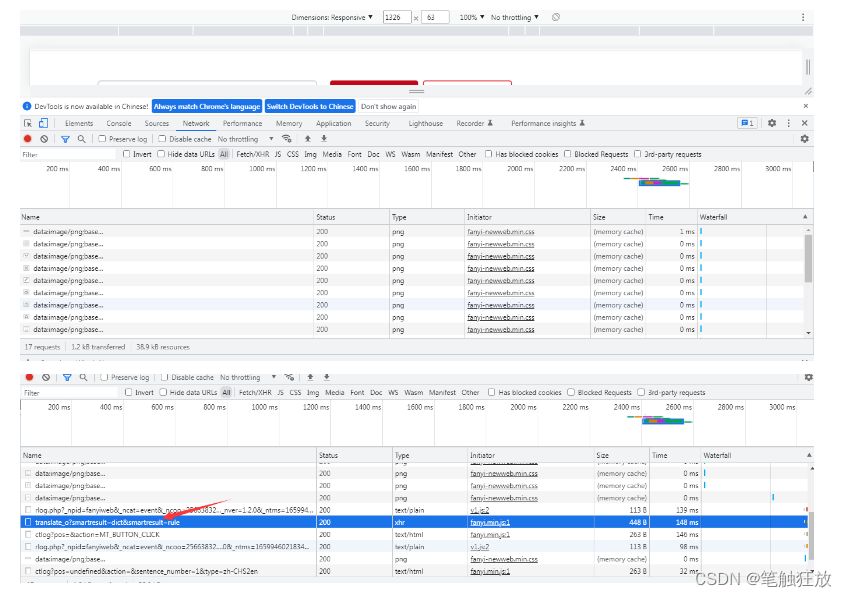
We then right-click the review element and switch to the network to view the request and response information for its network
Click on this response request to view its translation information
View response header information
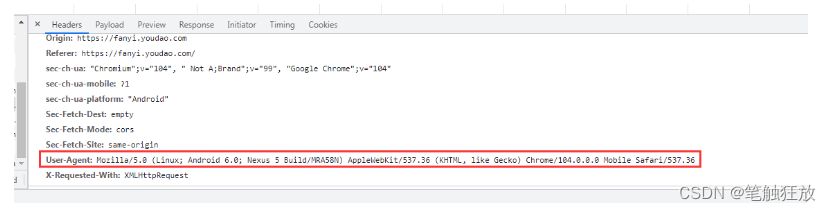
Browsers generally use the following information to determine whether it is a machine access, rather than human normal operation.

If the address accessed using Python is used, The User-Agent is defined as the Python-urllib/version number
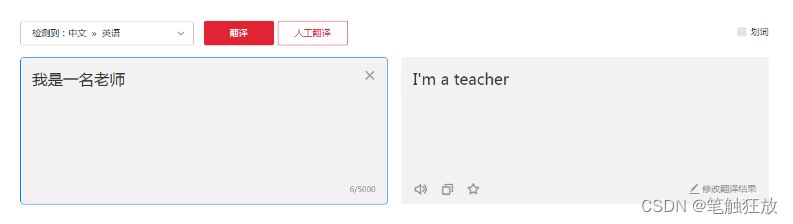
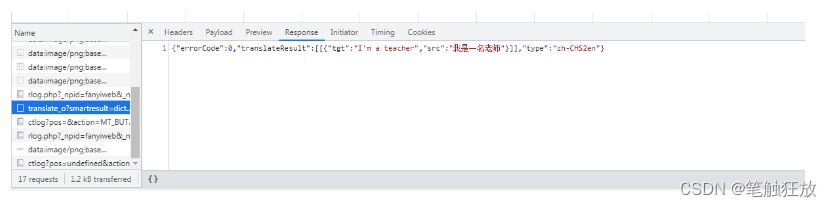
Just returned by observing the browser: {“errorCode”:0,”translateResult”:[{{“tgt”:” I’m a teacher”,”src”: “I’m a teacher”}]],”type”:”zh-CHS2en”}
Then this format is the json format, constructed by a mixture of {} and [], forming key-value pairs in between and separating key and value with colons.
# -*- coding:utf-8 -*-
”’
使用 POST 方式抓取 有道翻译
urllib2.Request(requestURL, data=data, headers=headerData)
Request 方法中的 data 参数不为空,则默认是 POST 请求方式
如果 data 为空则是 Get 请求方式
{“errorCode”:50}错误:
有道翻译做了一个反爬虫机制,就是在参数中添加了 salt 和 sign 验证,具体操作说明参考:
http://www.tendcode.com/article/youdao-spider/
”’
import urllib.request
import urllib.parse
import time
import random
import hashlib
import sys
# 字符串转 utf-8 需要重新设置系统的编码格式
def reload(sys):
sys.setdefaultencoding(‘utf8’)
# 目标语言
targetLanguage = ‘Auto’
# 源语言
sourceLanguage = ‘Auto’
headerData = {
‘Cookie’: ‘OUTFOX_SEARCH_USER_ID=-2022895048@10.168.8.76;’,
‘Referer’: ‘fanyi.youdao.com’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36’
}
# 语言类型缩写
languageTypeSacronym = {
‘1’: ‘zh-CHS 》 en’,
‘2’: ‘zh-CHS 》 ru’,
‘3’: ‘en 》 zh-CHS’,
‘4’: ‘ru 》 zh-CHS’,
}
# 翻译类型
translateTypes = [
‘中文 》 英语’,
‘中文 》 俄语’,
‘英语 》 中文’,
‘俄语 》 中文’
]
def startRequest(tanslateWd):
requestURL = ‘http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule’
client = ‘fanyideskweb’
timeStamp = getTime()
key = ‘ebSeFb%=XZ%T[KZ)c(sy!’
sign = getSign(client, tanslateWd, timeStamp, key)
data = { ‘i’: tanslateWd,
‘from’:sourceLanguage,
‘to’:targetLanguage,
‘client’:client,
‘doctype’:’json’,
‘version’:’2.1′,
‘salt’:timeStamp,
‘sign’:sign,
‘keyfrom’:’fanyi.web’,
‘action’:’FY_BY_REALTIME’,
‘typoResult’:’true’,
‘smartresult’:’dict’
}
data = urllib.parse.urlencode(data).encode(encoding=”utf-8″)
request = urllib.request.Request(requestURL, data=data, headers=headerData)
resonse = urllib.request.urlopen(request)
print(resonse.read().decode(“utf-8”))
# 生成时间戳
def getTime():
return str(int(time.time() * 1000) + random.randint(0, 10))
# 生成 Sign
def getSign(client, tanslateWd, time, key):
s = client + tanslateWd + time + key
m = hashlib.md5()
m.update(s.encode(‘utf-8’))
return m.hexdigest()
def getTranslateType(translateType):
global sourceLanguage, targetLanguage
try:
if translateType:
l = languageTypeSacronym[translateType].split(‘ 》 ‘)
sourceLanguage = l[0]
targetLanguage = l[1]
except:
print(‘翻译类型选择有误,程序将使用 Auto 模式为您翻译’)
if __name__ == ‘__main__’:
print(‘翻译类型:’)
for i, data in enumerate(translateTypes):
print(‘%d: %s’ %(i + 1, data))
translateType = input(‘请选择翻译类型:’)
getTranslateType(translateType)
tanslateWd = input(‘请输入要翻译的消息:’)
startRequest(tanslateWd)


