![[YOLOv7/YOLOv5 series algorithm improvement NO.11] The backbone network C3 is replaced by the lightweight network MobileNetV3](https://hmimicro.com/wp-content/uploads/2023/01/6f7d0f87d4ed14310e71e709eab9adfd.jpg)
Foreword
As the current advanced deep learning target detection algorithm YOLOv5, a large number of tricks have been assembled, but there is still room for improvement and improvement. Different improvement methods can be used for detection difficulties in specific application scenarios. The following series of articles will focus on how to improve YOLOv5 in detail. The purpose is to provide meager help and reference for those students who are engaged in scientific research who need innovation or friends who are engaged in engineering projects to achieve better results.
Solve the problem: YOLOv5 backbone feature extraction network adopts C3 structure, which brings a large amount of parameters, slow detection speed, and limited application. In some real application scenarios such as mobile or embedded devices, when such a large and complex model difficult to apply. The first is that the model is too large and faces the problem of insufficient memory. Second, these scenarios require low latency, or fast response. Imagine what terrible things will happen if the pedestrian detection system of a self-driving car is very slow. Therefore, it is crucial to study small and efficient CNN models in these scenarios, at least for now, although future hardware will become faster and faster. This paper attempts to replace the backbone feature extraction network with a lighter MobileNet network to achieve a lightweight network model and balance speed and accuracy.
principle:
Paper address: https://arxiv.org/abs/1905.02244.pdf
Code: https://github.com/LeBron-Jian/DeepLearningNote
MobileNet V3 related technologies are as follows:
1. Use MnasNet to search the network structure
2. Depth separable with V1
3. Using V2’s inverted residual linear bottleneck structure
4. Import SE module
5. The new activation function h-swish(x)
6. Two strategies are utilized in web search: resource-constrained NAS and NetAdapt
7. Modify the last part of V2 to reduce the calculation
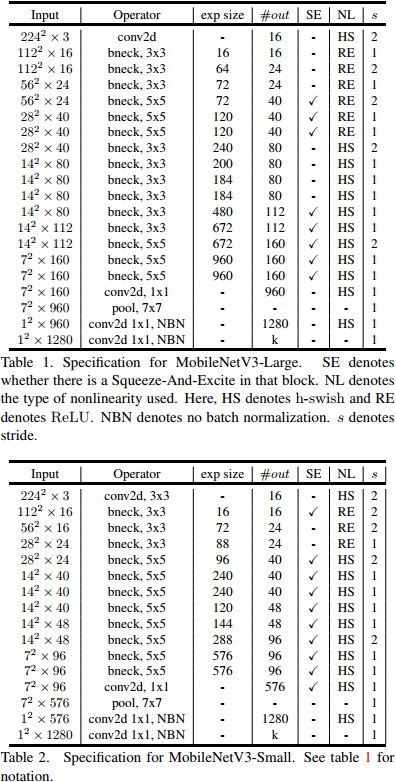
method:
The first step is to modify common.py and add the MobileNetV3 module. Part of the code is as follows.
class StemBlock(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=None, g=1, act=True):
super(StemBlock, self).__init__()
self.stem_1 = Conv(c1, c2, k, s, p, g, act)
self.stem_2a = Conv(c2, c2 // 2, 1, 1, 0)
self.stem_2b = Conv(c2 // 2, c2, 3, 2, 1)
self.stem_2p = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
self.stem_3 = Conv(c2 * 2, c2, 1, 1, 0)
def forward(self, x):
stem_1_out = self.stem_1(x)
stem_2a_out = self.stem_2a(stem_1_out)
stem_2b_out = self.stem_2b(stem_2a_out)
stem_2p_out = self.stem_2p(stem_1_out)
out = self.stem_3(torch.cat((stem_2b_out, stem_2p_out), 1))
return out
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
y = self.sigmoid(x)
return x * y
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class conv_bn_hswish(nn.Module):
“””
This equals to
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
“””
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = h_swish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MobileNetV3_InvertedResidual(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
super(MobileNetV3_InvertedResidual, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size – 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# Eca_layer(hidden_dim) if use_se else nn.Sequential(),#1.13.2022
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size – 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# Eca_layer(hidden_dim) if use_se else nn.Sequential(), # 1.13.2022
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y
Step 2: Register the module in yolo.py.
if m in [Conv, MobileNetV3_InvertedResidual, ShuffleNetV2_InvertedResidual, ]:
Step 3: Modify the yaml file
backbone:
# MobileNetV3-large
# [from, number, module, args]
[[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2
[-1, 1, MobileNetV3_InvertedResidual, [ 16, 16, 3, 1, 0, 0]], # 1-p1/2
[-1, 1, MobileNetV3_InvertedResidual, [ 24, 64, 3, 2, 0, 0]], # 2-p2/4
[-1, 1, MobileNetV3_InvertedResidual, [ 24, 72, 3, 1, 0, 0]], # 3-p2/4
[-1, 1, MobileNetV3_InvertedResidual, [ 40, 72, 5, 2, 1, 0]], # 4-p3/8
[-1, 1, MobileNetV3_InvertedResidual, [ 40, 120, 5, 1, 1, 0]], # 5-p3/8
[-1, 1, MobileNetV3_InvertedResidual, [ 40, 120, 5, 1, 1, 0]], # 6-p3/8
[-1, 1, MobileNetV3_InvertedResidual, [ 80, 240, 3, 2, 0, 1]], # 7-p4/16
[-1, 1, MobileNetV3_InvertedResidual, [ 80, 200, 3, 1, 0, 1]], # 8-p4/16
[-1, 1, MobileNetV3_InvertedResidual, [ 80, 184, 3, 1, 0, 1]], # 9-p4/16
[-1, 1, MobileNetV3_InvertedResidual, [ 80, 184, 3, 1, 0, 1]], # 10-p4/16
[-1, 1, MobileNetV3_InvertedResidual, [112, 480, 3, 1, 1, 1]], # 11-p4/16
[-1, 1, MobileNetV3_InvertedResidual, [112, 672, 3, 1, 1, 1]], # 12-p4/16
[-1, 1, MobileNetV3_InvertedResidual, [160, 672, 5, 1, 1, 1]], # 13-p4/16
[-1, 1, MobileNetV3_InvertedResidual, [160, 960, 5, 2, 1, 1]], # 14-p5/32 原672改为原算法960
[-1, 1, MobileNetV3_InvertedResidual, [160, 960, 5, 1, 1, 1]], # 15-p5/32
]
Results: I have done a lot of experiments on multiple data sets. The effect of different data sets is different. The map value has decreased, but the size of the weight model has decreased, and the number of parameters has decreased.
A preview: the next article will continue to share the sharing of network lightweight methods. Interested friends can pay attention to me, if you have any questions, you can leave a message or chat with me privately
PS: The replacement of the dry network is not only suitable for improving YOLOv5, but also can improve other YOLO networks and target detection networks, such as YOLOv4, v3, etc.
Finally, I hope that we can follow each other, be friends, and learn and communicate together.


